The Rise of Artificial Intelligence
in Go Programming
|
Since 2006, Go programming has made significant progress, in particular thanks to the Monte-Carlo method, but without being able to achieve professional level on the 19x19 board. The largest success of a bot (= Go playing software; from "robot") of the Monte-Carlo type was a win by "Crazy Stone" in a four stones handicap game against Ishida Yoshio 9p in 2013. In 2015 however, a paradigm shift in Go programming towards neural networks and deep learning occurred, eventually resulting in bots of superhuman strength. In October 2015, Google DeepMind's AlphaGo beat for the first time a professional human player (Fan Hui 2p, at that time European Champion) on the full size 19x19 board without handicap (5-0 in slow games and 3-2 in quick games). AlphaGo used a fundamentally different paradigm than earlier Go programs. It included very little "direct" instruction, and mostly used deep learning where AlphaGo played itself in hundreds of millions of games such that it could measure positions more intuitively. In March 2016, Google next challenged Lee Sedol 9p, considered the top player in the world in the early 21st century, to a five-game match. Leading up to the game, Lee Sedol and other top professionals were confident that he would win. However, AlphaGo defeated Lee in four of the five games. In May 2017, AlphaGo beat Ke Jie 9p, who at the time continuously held the world No. 1 ranking for two years, winning each game in a three-game match during the Future of Go Summit. DeepMind then announces that AlphaGo will no longer participate in other competitions and will be replaced by a learning tool for human players. In October 2017, DeepMind released a new version, called AlphaGo Zero, using no human knowledge (as all the versions before) but only from the rules of the game and self-learning. This significantly stronger version beat the previous one by 100 games to 0. |
Superhuman AI Bots and Igo Hatsuyōron 120
|
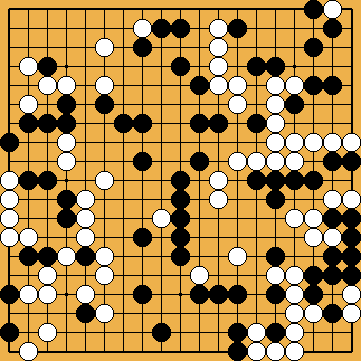
Since the success of AlphaGo Zero, different developers have attempted to replicate the approach of DeepMind's strongest program. "Leela Zero", an open-source community-based project, which also has reached superhuman strength in the meantime, was first released in October 2017, too. The first release of "KataGo" was published in early 2019. However, the modern Zero-trained bots do very poorly on Igo Hatsuyōron 120. This is because of its highly unusual shapes (e.g. unlike anything that would be likely to occur in a normal game), as well as the tightly-balanced large capturing races. Three obstacles are known that are potentially in the way of bots on Igo Hatsuyōron 120:
It is not known what can be done about obstacle #1; that's an open problem of machine learning research. How to improve obstacle #3 is another major unsolved question in machine learning.To better understand obstacles #2 and #3, we translate the bots' approach into an analogous human world: If a human Go player had never studied Igo Hatsuyōron 120 at all, they would also be very bad at it at first, particularly if they had to solve it alone with no outside help. And the reason the human would be bad is not because the concepts are fundamentally impossible for the human to learn. It's because the human has never seen this problem nor any of the exotic shapes therein before. How does a human go from being bad at the problem to being better? Well, as they study the problem, they learn about it in the process. With enough time, they start to understand better.
This is exactly what happened for 1,000 hours in the study group of Fujisawa Hideyuki, and also for many, many more hours in our three amateurs' research group. In comparison, how do modern AI bots behave? Let's draw an analogy: Suppose there were a human pro-strength Go player who had reached that strength via practical play only and never studied classical problems nor did any tsume go whatsoever where they would see any kind of the exotic shapes (e.g. the hanezeki in the lower right or the nakade at the left) of Igo Hatsuyōron 120. Then this human was sat down and given a few minutes thinking time and asked to make a move and decide who was ahead. Moreover, suppose that during these few minutes, every time they had finished reading out any variation and reached even a basic understanding e.g. of the hanezeki, the only thing they would remember of that variation was how much they liked the result, and aside from that any general new understanding of the situation gained from that reading would be erased by a magical mind wipe. The human were put back to as if they had never seen such a position again for reading the next possible variation. With respect to learning in real-time, modern bots are sort of like those patients with memory disorders who remember their long-ago experience very well but are perpetually incapable of learning new things or making new memories. Suffering from such a condition would obviously greatly harm any player's ability to play well in such a situation. Would you really expect that human to find many moves of the correct solution sequence, not to mention solving the problem? Certainly not. |
KataGo & Igo Hatsuyōron 120
|
But why the hell aren't our memory disorder patients handicapped so prominently in real games? This is because over the millions of games of training, any position likely to occur in a real game, they have seen enough similar positions already. Despite being like a human whose understanding and memory of the current position is constantly wiped to nothing on every new move and every new subvariation of reading within each move, their judgment is shaped well enough by past training that they don't need to fundamentally learn anything new and specific to this position to still play it well. This implies that we have to address obstacle #2 if we want a bot to do well at Igo Hatsuyōron 120.
Here comes the developer of KataGo into play. He was confident that if obstacle #2 can just be fixed by specific training, fixing obstacle #3 (and maybe obstacle #1 also) will become unnecessary. If a bot is bad at something because it has literally never seen such a position before, then it has to be trained specifically on that position. Therefore, KataGo was trained specifically on this problem for one week starting from the strongest official network, conducting its selfplay training using the AlphaZero loop from random positions taken from the Igo Hatsuyōron 120 variations of this website (with over 18,000 positions) instead of from the empty board. It is far from clear if KataGo has reached an optimal understanding after that week, but, at a minimum it seems to understand clearly the main elements of the problem, independently re-confirms many human moves and variations, and has a small number of exciting new move suggestions that have a decisive impact on the final result. We present these findings in part three "THE EVOLUTION OF AMATEURS' KNOWLEDGE" KataGo's findings will be shown at an equivalent moment in the course of Our Solution. KataGo has several changes in the order of moves, because e.g. it does not have a solid understanding of what a "technical correct timing" of a forcing move is.As a matter of course, KataGo also found improvements for several of our amateurish subvariations alongside our variation tree, favouring one side or the other. However, none of these corrections affected the outcome of the game. A developer's report on his project can be found in the blog post Deep-Learning the Hardest Go Problem in the World. The neural network learned many things in parallel over the course of the week, but it was clear that different moves were "discovered" or general understanding of different aspects "converged" at different times of the week when interacting with KataGo to see its move suggestions. The number of variations in this problem is immense, so of course it was not possible to manually analyze all variations to see what KataGo did or did not understand at each point in training, but anecdotally:
The game now ends with two points for White by area scoring (used by KataGo), but with only one point for White by territory scoring (used in Japan). Please refer to KataGo's Bad Shape Move Again – Flying Below the Radar of Area Scoring (2019) for details. You might wonder to what extent Black still has the opportunity for a sudden turnaround. Personally, I doubt that there could be hidden points on the board left, that Black could exploit for himself with advantage. KataGo "found" my guzumi, which locally destroys three points of White territory, last. If there had been another beneficial spot for Black on the board, KataGo would have identified it in parallel. Please note that – due to the granularity of two points of the final scores under area scoring – KataGo would be oblidged to identify a drawn game. However, KataGo is sensitive to this crucial two-points difference in the final result of the game, so it seems to be excluded that KataGo overlooked the golden opportunity to make this happen. |
KataGo & Inoue Dōsetsu Inseki
|
In his afterword to Igo Hatsuyōron (as far as I understand it correctly), Inoue Dōsetsu Inseki wrote that only the one can be named a master of the game, who has gone beyond the borders of their current thinking. And haven't the Artificial Intelligence based programs significantly surpassed human professional players now? When seeing the (current) final score of "White wins by one point", which is really not a "correct" solution for a goal "Black to play and win", the following thought crossed my mind. The original of Igo Hatsuyoron does not give any aims to achieve, but has either "Black to play" or "White to play" only. There is another possible explanation for the fact that there are 71 White, but only 70 Black stones on the board – leaving aside the capture of one Black stone before the problem's setup: It was White – and not Black– who initiated the game. Under this assumption, the result would become "Jigo" (a drawn game), just because that supposed prisoner suddenly vanished. Would it be so very unimaginable that -- especially in the no-komi era -- Inoue Dōsetsu Inseki regarded a draw to be the "ideal" result for his masterpiece? In retrospect, it seems that Inoue Dōsetsu Inseki was a most excellent analyst of all the blind spots of the human professional mind. It also seemed to be much easier to win the problem with Black than with White. So why not have "Black to play" if one wants to challenge the frontier crossing ability of human professional Go players? Especially because it would have been quite trivial to come up with a goal "Black to play and achieve a drawn game": Just add the first move of Our Solution to the problem's setup and then reverse the colours.
|
|
|